
تفکیک داده ها (Split File) در SPSS
تفکیک فایل داده در SPSS
این نوشته در خصوص تفکیک داده ها (Split File) در SPSS می باشد. قابل ذکر است در نرمافزار SPSS، مجموعه داده (Dataset) به جدولی گفته میشود که شامل اسامی متغیرها و مقادیر آنها است.
معمولا یک مجموعه داده، جدولی است که سطرها نمایانگر مشاهدات (Cases) و ستونها نیز متغیرها (Variables) را نشان میدهد.
نوع متغیرها در نرمافزار SPSS یا به صورت کمی (Quantitative) است یا کیفی (Qualitative).
البته متغیرهای کیفی به دو دسته اسمی (Nominal) و ترتیبی (Ordinal) طبقهبندی و متغیرهای کمی نیز با مقیاس (Scale) در SPSS شناخته میشوند.
اغلب از متغیرهای اسمی و ترتیبی برای تفکیک جامعه آماری و یا نمونهها استفاده میشود.
به این ترتیب ممکن است گاهی اوقات آنها را متغیرهای طبقهای (Categorical Variable) نیز بنامیم.
بر همین اساس میتوانیم تحلیلها آماری را برای دستههای خاصی از جامعه آماری به تفکیک انجام دهیم.
برای تفکیک فایل داده در SPSS به بخشهای جداگانه روشهای مختلفی وجود دارد.
روشهای تفکیک داده ها
انتخاب مشاهدات: به کمک دستور Select Cases قادر هستیم که بعضی از مشاهدات را انتخاب کرده و محاسبات و تحلیلهای آماری را روی این گروه خاص اجرا کنیم.
تعیین متغیر تفکیکی: به کمک دستور Split File، از یک یا چند متغیر طبقهای برای تفکیک جامعه استفاده کرده و میتوانیم با یکبار اجرای دستورات تحلیلی آماری، برای همه گروههای تفکیک شده، نتایج تحلیلها آماری را بدست آوریم.
تفکیک فایل داده:
روش دیگر، تفکیک مجموعه داده به چندین فایل است که با دستور Split Into Files صورت میگیرد. در نتیجه میتوان روی هر یک از مجموعه دادهها، تحلیل آماری یا روش خاصی را اجرا کرد.
مجموعه دادهای را در نظر بگیرید که شامل دو متغیر طبقهای (کیفی) و یک متغیر کمی (Scale) است.
برای مثال ممکن است این فایل، شامل اطلاعات مربوط به درآمد افراد با متغیر income به عنوان متغیر کمی و متغیرهای وضعیت اشتغال (بازنشسته و شاغل) به همراه جنسیت (زن یا مرد) به عنوان متغیرهای کیفی باشند.
چنین فایلی را در تصویر زیر مشاهده میکنید.
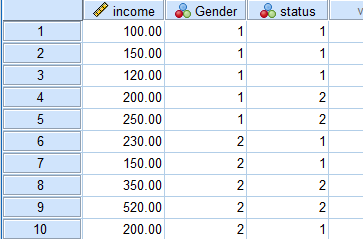 برگه نمایش دادهها Data View
برگه نمایش دادهها Data View
در تصویر زیر نحوه معرفی این متغیرها نیز نمایش داده شده است.
 تعریف متغیرها در Variable View
تعریف متغیرها در Variable View
قرار است میانگین درآمد را برای گروههای بازنشسته و شاغل و همچنین زن و مرد محاسبه و به عنوان خروجی در پنجره Output نمایش دهیم.
این کار را به کمک روشهای تفکیکی که در بالا به آن اشاره شد انجام خواهیم داد.
نکته: اگر بخواهید به جای نمایش مقادیر، برچسبهای تعریف شده برای هر یک از مقادیر متغیرهای Gender و status را نمایش دهید باید از فهرست View گزینه Value Labels را انتخاب کنید.
انتخاب مشاهدات با Select Cases
برای دسترسی به دستور انتخاب مشاهدات، از فهرست Data گزینه Select Cases را انتخاب میکنیم. پنجرهای به صورت زیر ظاهر میشود.
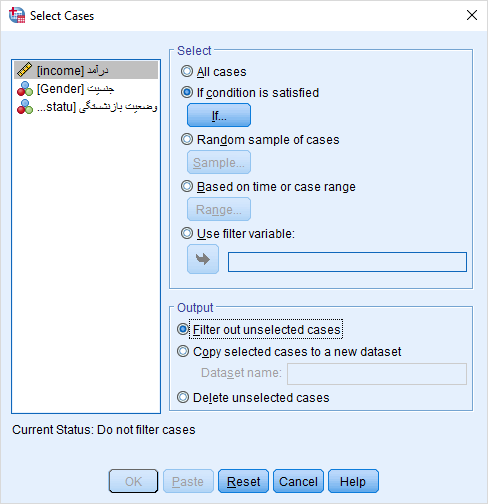 پنجره انتخاب مشاهدات، Select Cases
پنجره انتخاب مشاهدات، Select Cases
در قسمت چپ، لیست متغیرهای موجود در مجموعه داده نمایش داده است. در قسمت سمت راست این پنجره نیز نحوه انتخاب مشاهدات مشخص شده است. در فهرست زیر به معرفی این گزینههای کادر Select خواهیم پرداخت.
-
گزینه All cases:
همه مشاهدات در محاسبات و تحلیلهای آماری به کار گرفته میشوند.
-
گزینه if condition is satisfied:
با انتخاب این گزینه برای مشخص کردن مشاهداتی که باید در تحلیلهای آماری آتی در نظر گرفته شوند از یک عبارت شرطی استفاده میشود. هر مشاهدهای که شرط گفته شده برایش صادق باشد، انتخاب شده و برای انجام تحلیلهای آماری بعدی SPSS از آنها بهره میبرد. این شرط میتواند براساس یک یا چند متغیر نوشته شود. حتی میتوان براساس مقدارهای یک متغیر طبقهای نیز مشاهدات را برای انتخاب محدود کرد.
-
گزینه Random sample of cases:
انتخاب یک نمونه تصادفی از مجموعه داده موجود توسط این گزینه صورت میگیرد. اگر بخواهیم به طور تصادفی یک نمونه از مشاهدات موجود ایجاد کنیم، این گزینه بهترین روش خواهد بود.
-
گزینه Based on time or case range:
اگر لازم است که دنبالهای خاصی از مشاهدات انتخاب شوند این گزینه کار ساز است.
برای مثال ممکن است بخواهیم برای انجام تحلیل آماری فقط از مشاهدات ۱۰ تا ۱۰۰ مورد استفاده قرار گیرند. به این ترتیب با ذکر این مقادیر، دامنه مشاهدات مورد نظر را محدود خواهیم کرد.
-
گزینه Use filter variable:
به کمک این گزینه و معرفی یک متغیر دو وضعیتی (مثلا با مقدار ۰ و ۱) همه مشاهداتی که در این متغیر مقداری برابر با صفر دارند کنار گذاشته شده و بقیه مورد استفاده خواهند بود.
مثال – تفکیک داده ها (Split File) در SPSS
در این قسمت قرار است میانگین درآمد را برای گروه آقایان محاسبه کنیم و نمایش دهیم. همین عمل را هم برای گروه خانمها نیز اجرا خواهیم کرد. پس مشخص است که متغیری که باعث تفکیک مشاهدات خواهد شد، متغیر Gender است. تنظیمات پنجره Select cases را براساس انتخاب گزینه If، مطابق با تصویر زیر در میآوریم.
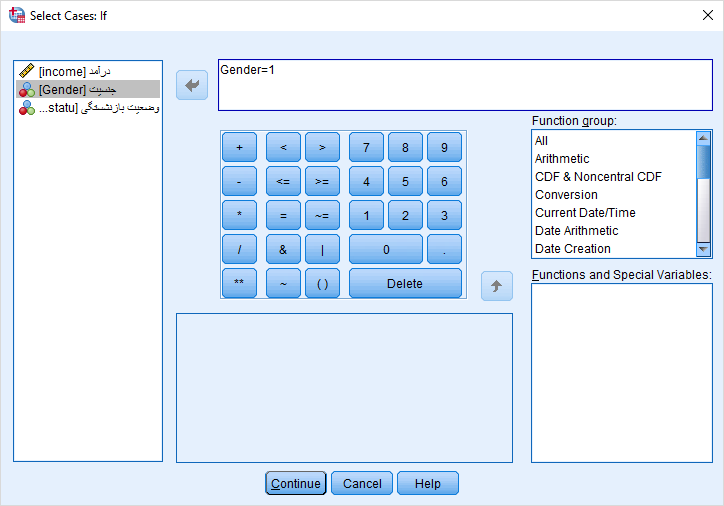
پنجره شرط برای انتخاب مشاهدات
به یاد دارید که مقدار جنسیت برای آقایان با مقدار ۱ مشخص شده بود. به همین علت در شرط نیز مقایسه مقدار متغیر Gender را با ۱ انجام دادهایم.
نکته۳:
اگر بخواهید از کدهای برنامهنویسی در SPSS برای انجام این امر استفاده کنید باید در پنجره Syntax دستورات زیر را وارد کنید.
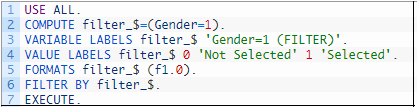
هنگامی که به وسیله دستور Select Cases، مشاهداتی را انتخاب میکنید، روی شماره مشاهدات انتخاب نشده در پنجره Data View، خط موربی دیده میشود که به معنی کنار گذاشته شدن آنها در تحلیلهای آتی است.
حال در پنجره Data View دیده میشود مشاهداتی که در ستون Gender مقداری برابر با ۲ دارند خط خوردهاند.
به این ترتیب فقط مشاهداتی که مربوط به آقایان هستند انتخاب شدهاند.
این وضعیت در تصویر زیر دیده میشود.
همانطور که مشاهده میکنید، یک متغیر جدید به نام $_filter ساخته شده که از نوع متغیرهای سیستم (System Variable) است و نشان میدهد که کدام مشاهدات انتخاب شدهاند.
مقدار این متغیر برای مشاهدات انتخاب نشده برابر با صفر (Not Selected) و در غیر اینصورت برابر با ۱ (Selected) است.
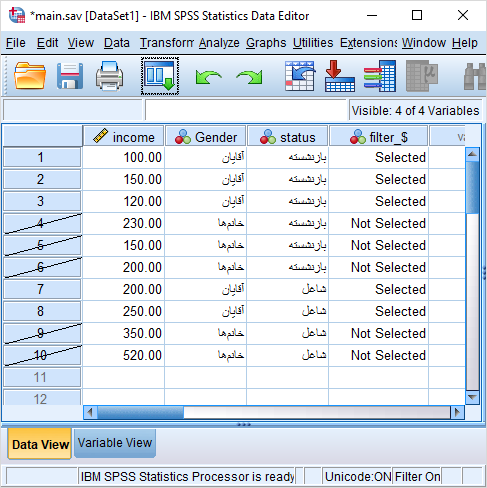
نمایش مشاهدات انتخابی به همراه متغیر $_filter
اکنون محاسبه میانگین را به کمک دستور Descriptive انجام میدهیم. نتیجه به صورتی که در تصویر زیر دیده میشود، خواهد بود.
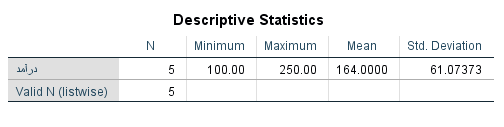
آمارهای توصیفی برای درآمد آقایان
همین عملیات را هم برای خانمها انجام خواهیم داد. دقت کنید که برای انتخاب خانمها در مجموعه داده کافی است که شرط مربوط به جنسیت را براساس مقدار ۲ بنویسیم.
با اجرای دستور Descriptive آمارههای توصیفی برای این گروه از مشاهدات ظاهر خواهد شد.
واضح است که میانگین درآمد در بین آقایان و خانمها تفاوت دارد.
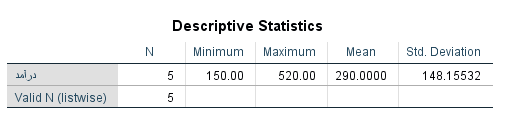
آمار توصیفی برای درآمد خانمها
نکته۴:
فراموش نکنید پس از انجام تحلیلها آماری، تنظیمات پنجره Select Cases را به حالت عادی در آورید. به این منظور فقط کافی است گزینه اول یعنی All cases را انتخاب و دکمه OK را در پنجره مربوطه کلیک کنید.
تفکیک داده ها (Split File) در SPSS
شیوه دیگری که برای انجام تحلیلهای آماری روی دستههای مختلفی از مشاهدات وجود دارد، استفاده از دستور Split File از فهرست Data به منظور تفکیک فایل داده در SPSS است.
به این ترتیب میتوانید به منظور مقایسه یا تهیه خروجی جداگانه از محاسبات روی هر دستهای از مشاهدات که توسط یک متغیر طبقهای مشخص میشود، از دستور Split File بهره ببرید.
با اجرای این دستور پنجرهای به مانند شکل زیر ظاهر میشود. باز هم متغیرها در کادر سمت چپ و جزئیات دستور Split File در کادر سمت راست دیده میشود.
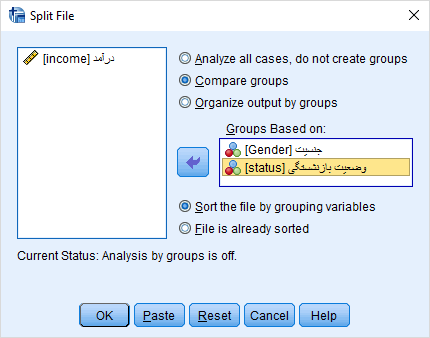 پنجره تفکیک فایل-Split File
پنجره تفکیک فایل-Split File
در ادامه به صورت فهرست وار به معرفی گزینههای این پنجره خواهیم پرداخت.
گزینه Analyze all cases, do not create groups:
انتخاب این گزینه باعث میشود که هیچ گونه طبقه و گروهبندی صورت نگیرد و تحلیل آماری روی همه مشاهدات انجام شود.
گزینه Compare groups:
با انتخاب این گزینه، باید متغیری که وظیفه تفکیک مشاهدات را دارد، در کادر Groups Based on مشخص کنید.
برای مثال اگر وضعیت بازنشستگی را در این کادر قرار دهیم، تحلیل آماری بعدی برای هر دو گروه شاغل و بازنشسته انجام شده و به منظور مقایسه نتایج، در هر مرحله یک جدول مقایسهای بین دو گروه تشکیل میشود.
به این ترتیب برای مثال اگر دستور تهیه جدول و نمودار فراوانی را دادهاید و متغیر وضعیت بازنشستگی را به عنوان متغیر تفکیکی معرفی کردهاید، ابتدا جدول فراوانی برای گروه شاغلها و بازنشستهها ایجاد شده سپس برای مقایسه نمودار فراوانی این دو گروه هیستوگرام ترسیم میشود.
پس مشخص است که هر بخش از خروجی برای هر گروه در کنار هم تولید میشود.
گزینه Organize output by groups:
اگر میخواهید برای هر طبقه یا دسته تمامی خروجیها به تفکیک حاصل شود، این گزینه را انتخاب کنید.
به این ترتیب برای مثال اگر دستور تهیه جدول و نمودار فراوانی را دادهاید و متغیر وضعیت بازنشستگی را به عنوان متغیر تفکیکی معرفی کردهاید، ابتدا جدول و نمودار فراوانی برای گروه شاغلها ایجاد شده سپس برای گروه بازنشستهها جدول و نمودار ترسیم میشود.
پس مشخص است که همه بخشهای خروجی برای هر گروه جداگانه تولید و نمایش داده میشود.
گزینه Sort the file by grouping variables:
فعال بودن این گزینه باعث میشود که مجموعه داده براساس متغیری که در قسمت Groups Bases on معرفی شده، مرتب شود.
به این ترتیب اگر متغیر وضعیت بازنشستگی برای تفکیک معرفی شده باشد، در پنجره Data View ابتدا مشاهداتی که مربوط به شاغلین است ظاهر شده سپس افراد بازنشسته دیده میشوند.
به این ترتیب نظم ورود دادهها تغییر خواهد یافت و مشاهدات نسبت به شماره ردیفها جابجا خواهند شد.
گزینه File is already sorted:
ممکن است بخواهید که نظم که قبلا برای مشاهدات در نظر گرفتهاید تغییر نکند.
به همین علت کافی است با انتخاب این گزینه، از مرتبسازی مجموعه داده توسط متغیر طبقهای در SPSS جلوگیری کنید.
به این ترتیب نظم مجموعه داده به حالت اولیه خود حفظ خواهد شد و مشاهدات نسبت به شماره ردیفها جابجا نخواهند شد.
نکته۵:
توجه داشته باشید که میتوان بیش از یک متغیر تفکیکی را در کادر Groups Based on قرار داد.
به این ترتیب به ازاء هر سطح از متغیرهای طبقهای خروجی جداگانهای تولید خواهد شد.
این کار برای مقایسههای ترکیبی مناسب است.
برای مثال اگر جنسیت و وضعیت بازنشستگی را در این کادر قرار دهیم، خروجیها شامل میانگین درآمد خانمهای بازنشسته، خانمهای شاغل، آقایان بازنشسته و آقایان شاغل خواهد بود.
در انتهای این پنجره نیز وضعیت به کارگیری دستور Split File مشخص شده است.
اگر متغیر یا متغیرهایی در کادر Groups Based on قرار گرفته باشند، نام آنها در این قسمت دیده میشود.
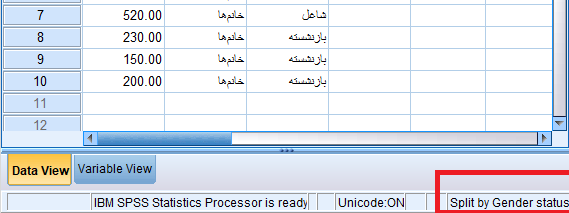
نمایش وضعیت تفکیک فایل
به منظور تفکیک فایل به کمک دستورات SPSS کافی است در پنجره Syntax کدهایی به مانند زیر را وارد و اجرا کنید.

مثال
محاسبه میانگین درآمد را برای گروههای خانمها و آقایان به تفکیک وضعیت بازنشستگی
پس مشخص است که متغیری که باعث تفکیک مشاهدات خواهد شد، متغیر Gender و status است.
تنظیمات پنجره Split File را مطابق با تصویر بالا انجام دادهایم.
حال در نوار وضعیت پنجره Data View دیده میشود که مشاهدات براساس این دو متغیر تفکیک شدهاند.
نکته۶:
متغیرهایی که در کادر Groups Based on به کار رفتهاند در هیچ تحلیل دیگری مورد استفاده قرار نگیرند.
زیرا شما آنها را مبنای طبقهبندی در نظر گرفتهاید و SPSS قادر به محاسبه براساس آنها نیست.
اکنون محاسبه میانگین را به کمک دستور Descriptive انجام میشودو نتیجه به صورت زیر خواهد بود.
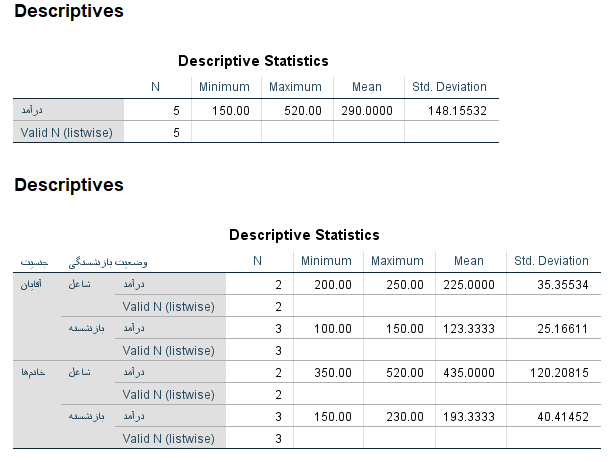
آمار توصیفی برای ترکیب گروههای زنان و مردان با وضعیت بازنشستگی
این طور به نظر میرسد که میانگین درآمد بازنشستهها هم در گروه آقایان و هم خانمها از شاغلین کمتر است.
ولی در بین گروه شاغلین متوسط درآمد خانمها تقریبا دو برابر آقایان است.
نکته۷:
از آنجایی که حجم نمونه کم و دادههای به صورت تصادفی هستند، ممکن است نتایج حاصل با واقعیت همخوانی نداشته باشد.
تفکیک فایل داده یا دستور Split info Files
آخرین ابزار و روشی که برای تفکیک مجموعه داده پیشنهاد میکنیم، تفکیک آنها در فایلهای مجزا با دستور تفکیک فایل داده در SPSS است.
به این ترتیب برای هر یک از گروههایی که توسط ترکیب سطوح مختلف متغیرهای طبقهای بوجود میآید، فایلهای جداگانه ساخته خواهد شد.
برای دسترسی به این دستور کافی است از فهرست Data گزینه Split into Files را انتخاب کنید.
به این ترتیب پنجرهای مانند تصویر زیر ظاهر خواهد شد.
در کادر سمت چپ یعنی Variables اسامی متغیرهایی که برای تفکیک مناسب هستند ظاهر شده است.
نکته :
در این لیست خبری از متغیر income نیست.
زیرا این متغیر از مقیاس (Scale) بوده و برای طبقهبندی و گروهبندی مشاهدات مناسب نیست.
واضح است در اینجا که فقط متغیرهایی از نوع اسمی (Nominal) یا ترتیبی (Ordinal) مناسب بوده و در این لیست ظاهر میشوند.
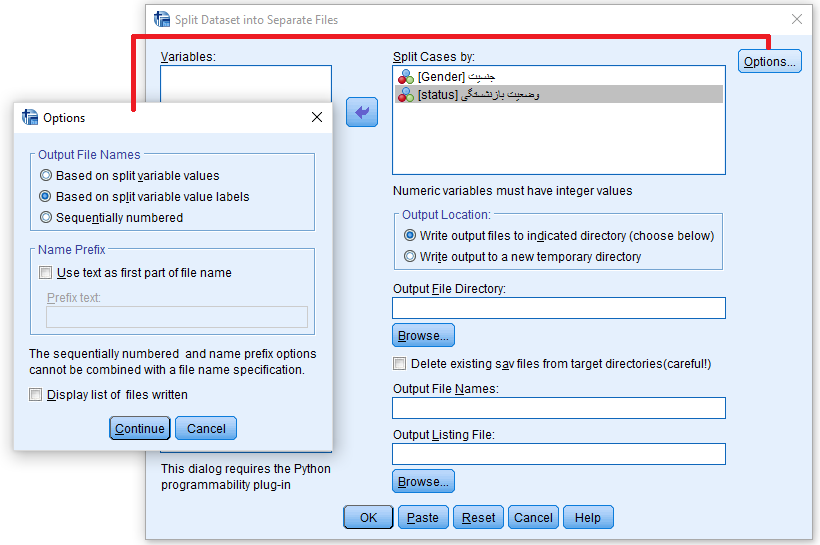 پنجره تفکیک دادهها در SPSS به چندین پرونده با دستور Split into Files
پنجره تفکیک دادهها در SPSS به چندین پرونده با دستور Split into Files
متغیرهایی که برای تفکیک فایل داده در SPSS لازم هستند را در کادر Split Cased by قرار دهید.
توجه دارید که در این قسمت میتوان بیش از متغیر طبقهای را هم قرار داد.
البته متغیرهایی که از نوع عددی هستند، باید شامل عددهای صحیح باشند.
در کادر Output Location با انتخاب گزینه (Write output files to indicated directory (choose below
محلی را که به عنوان پوشه ذخیرهسازی فایلهایی اطلاعاتی جدید است، در کادر Output File Directory مشخص میکنید.
برای این کار میتوانید از دکمه Browse هم کمک بگیرد.
با انتخاب گزینه Write output to a new temporary directory، محل و نام فایلهای حاصل از تفکیک مجموعه داده طی گزارشی توسط SPSS برایتان ظاهر میشود.
کد اجرایی برای انجام دستور Split into Files
مطابق با تصویر بالا در ادامه دیده میشود.
کافی است که این دستورات را در پنجره Syntax وارد و اجرا کنید.
البته دقت داشته باشید که محل قرارگیری فایلهای ایجاد شده در پوشه Desktop تعیین شده است.
![]()
سایر گزینه ها – تفکیک داده ها (Split File) در SPSS:
گزینه Based on split variable values:
با انتخاب این گزینه اسامی فایلها برگرفته از مقادیر یا سطوح متغیرهای تفکیکی خواهد بود. برای مثال اگر قرار باشد که فایلی برای ثبت اطلاعات مشاهدات مربوط به خانمها ایجاد شود، نام فایل با کد ۲ شروع خواهد شد.
گزینه Based on split variable value labels:
این گزینه باعث میشود که به جای مقدار سطوح متغیر تفکیکی از برچسب مقادیر (Value Label) برای نامگذاری فایلها استفاده شود.
به این ترتیب اسامی فایلها به صورت بازنشسته-آقایان، یا شاغل-خانمها خواهد بود.
گزینه Sequentially numbered:
این گزینه باعث میشود که فایلها به صورت خودکار و دنباله هم شمارهگذاری شوند.
مشخص است که این شمارهها همان نام فایلها خواهد بود.
همچنین با تعیین یک پیشوند برای فایلها در قسمت Name Prefix و انتخاب گزینه Use text as first part of file name، متنی را در کادر Prefix text مشخص میکنید.
این متن سرنام، اسامی همه فایلهای ایجاد شده خواهد بود.