
آزمون T مستقل در spss
آزمون T مستقل در به ارزیابی مسئله ها تحلیل آماری می پردازد که آیا میانگین یا معدل دو گروه یا دو وضعیت از لحاظ آماری تفاوتی با هم دارند یا نه.
این آزمون، از آزمونهای قدرتمند محسوب میشوند که برای دادههای پارامتری و دادههای تحلیل آماری که معمولاً توزیع میشوند استفاده میگردند.
نکته:
از آزمونهای t برای تحلیل آزمایشات ساده یا انجام مقایسات ساده بین سطوح متغیر وابسته استفاده میشود.
آزمون t تحلیل آماری بر دو قسم است:
۱) آزمون t وابسته
۲) آزمون t اندازهگیری مکرر( که به آن آزمون t نمونههای جفت یا مرتبط نیز گفته میشود)
تعریف آزمون t وابسته:
در صورتی که شما دو گروه جدا از افراد یا موردهایی را در یک طرح بین شرکتکنندگان (مثل زن و مرد، گروه آزمایش و کنترل) داشته باشید استفاده میشود.
تعریف آزمون t اندازهگیری مکرر تحلیل آماری( که به آن آزمون t نمونههای جفت یا مرتبط نیز گفته میشود):
در شرایطی استفاده میشود که شرکت کنندگان دادههایی برای تمام سطوح و وضعیت متغیر مستقل در یک طرح درون-شرکت کنندگان ارائه میدهند (مثلاً قبل یا بعد از مداخله).
در این نوشته آموزش آزمون t مستقل را فرا خواهیم گرفت.
در مطلب دیگری به آزمون t اندازهگیریهای مکرر پرداخته خواهد شد.
دلیل اینکه به این دو موضوع به طور جداگانه خواهیم پرداخت این است که فایل دادهها متفاوت از هم هستند،
از آپشنهای منو جداگانه در SPSS استفاده میکنند، و خروجی متفاوت از هم دارند.
در نمونههای زیر نشان میدهیم که پس از ایجاد فایل دادهها چه اتفاقی رخ میدهد.
استفاده از آزمون t مستقل در SPSS
این خودآموز به شما میگوید که چگونه آزمون t مستقل را اجرا یا تفسیر کنید.
مثال براساس مطالعۀ شوتلند و استراو (۱۹۷۶) میباشد.
این افراد درصدد بودند تا تأثیر رابطۀ دریافتی تحلیل آماری بین نزاع یک زوج بر احتمال مداخلۀ شخص دیگر را کشف کنند.
برای آزمون این مسئله شرکتکنندگان به دو گروه تقسیم شدند و از آنها خواسته شد تا فیلم نزاع دو شخص را تماشا کنند.
فیلمها به جز برای یک خط تعیینکننده مشابه هم بود.
یک گروه فریاد زدن قربانی را میبیند که می گوید” تنهایم بگذار، تو را نمیشناسم”.
در حالی که گروه دیگر همان شخص را میبیند که میگوید” تنهایم بگذار، نباید با تو ازدواج میکردم”.
از شرکتکنندگان خواسته شد تا میزان مداخلۀ خود را براساس مقیاس ۱-۵ ارزیابی کنند. دادهها را میتوان به شرح زیر در فایل SPSS گنجاند:
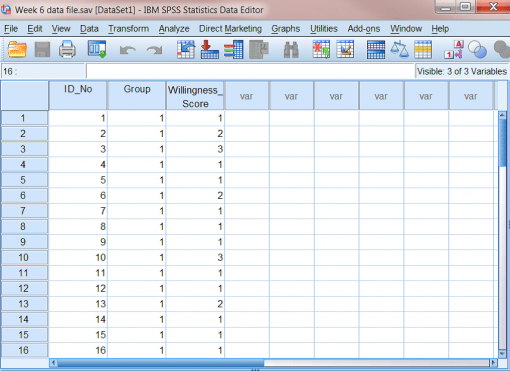
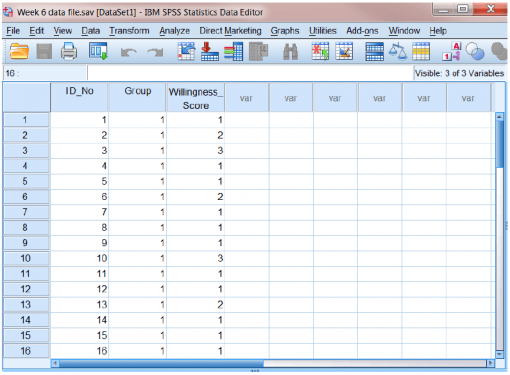
برای آزمون t مستقل، فایل داده ها تحلیل آماری باید دارای حداقل دو ستون باشد:
– یک ستون برای متغیر مستقل
– یک ستون برای متغیر وابسته
- متغیر مستقل از کدها برای اختصاص دادن عضویت گروه به هر سطح یا وضعیت استفاده می کند. به عنوان مثال، از “۱” برای گروه کنترل و “۲” برای گروه آزمایشی می کند. هر ستون، متغیر متفاوتی را به نمایش می گذارد و هر ردیف حاوی داده های یک شرکت کننده است. ستون های مختلف داده های زیر را نشان می دهد
- متغیر ID_No به شماره شناسۀ اختصاص یافته به هر شرکت کنندهتحلیل آماری اشاره دارد. ما از اعداد به عنوان شناساگر به جای اسامی شرکت کنندگان استفاده می کنیم. این شیوه کمک می کند تا داده ها را بدون اینکه نام شرکت کنندگان فاش شود گردآوری کنیم. این شیوه در روانشناسی بویژه زمانی که گردآوردی داده ها با حاسیت زیاد مواجه است بسیار مفید و کاربردی است.
تعریف متغییر مستقل:
گروه متغیر به ما می گوید که شرکت کنندگان در چه وضعیت آزمایشی قرار دارند که به آن متغیر مستقل گفته می شود. IV برای آزمون t مستقل همیشه داده های مطلق (یا اسمی) است.
اکنون سفارش دهید
مثال آزمون T مستقل در spss:
ما از کد “۱” برای شرکت کنندگانی استفاده کردیم که زوج در حال نزاع را با هم غریبه در نظر گرفتند و کد “۲” برای کسانی که بین آنها رابطه ایی لحاظ کردند.
در SPSS، به این کدها صفحۀ Variable View گفته می شود.
برای آشنایی با این کدها به خودآموز اول با عنوان افزودن متغیرها مراجعه کنید.
Willingness_Score یک نوع رتبه بندی خودسنجی است که به این می پردازد که شرکت کنندگان تا چه اندازه مایل به مداخله در نزاعی که شاهدش هستند می باشند.
این متغیر وابسته ما می باشد.
در مثالی که بیان کردیم، این نمره یا اسکور تحلیل آماری با استفاده مقیاس ۵ امتیازی لیکرت رتبه بندی می شود که مقیاس بالاتر نشانگر احتمال بیشتر مداخله می باشد.
همانطور که در ابتدای خودآموز گفته شد، آزمون t مستقل، نمرات دو گروه را بر اساس یک متغیر خاص با هم مقایسه می کند.
- در این مورد، می خواهیم نمرات رضایت و میل دو گروه آزمایشی را با هم مقایسه کنیم.
برای آغاز تحلیل، ابتدا بایدد روی منوی Analyze کلیک کنیم،
- گزینۀ Compare Means
- و سپس گزینۀ فرعی Independent-Samples T Test را انتخاب کنیم.
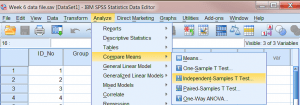
پس از آن کادر دیالوگ Independent Samples T-Test باز می شود.
در اینجا باید به SPSS بگوییم که قصد داریم کدارم متغیرها را تحلیل کنیم. شاید متوجه شوید که متغیرهای شما در حال حاضر در پنجرۀ چپ قرار دارند.
به محض اینکه Variable Labels(برچسب های متغیر) نمایش داده شد، به جز Variable Names (اسامی متغیر) کوتاهتر، خواندن بقیه دشوار است.
برای تغییر این وضعیت، با موس روی پنجره کلیک راست کنید و گزینۀ نمایش را به شرح زیر به ‘Display Variable Names’ تغییر دهید:
بدین ترتیب لیست متغیر تغییر می کند و خواندن آن راحت تر می شود.
اکنون می توانید کار تحلیل را شروع کنید. ابتدا، باید به SPSS بگوید که Grouping Variable (یا IV) شما چیست.
برای ای کار، متغیر Group را SELECT یا انتخاب کنید و سپس آن را با استفاده از پیکان آبی در قسمت پایین کنار کادر Grouping Variable به قاب پایینی سمت راست ببرید.
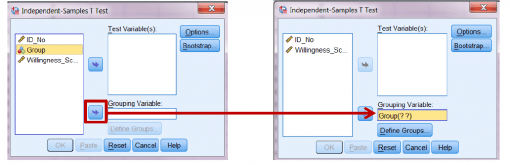
Groupاکنون دو علامت سئوال در کنار خود دارد.
این به این معنی است که باید به SPSS بگویید کدام وضعیت ها را می خواهید مقایسه کنید.
همین که وضعیت های IV (دسته بندی های گروهی) با کدهای عددی تحلیل آماری وارد SPSS شد،
باید به SPSS بگویید کدام کدها وضعیت هایی را که می خواهید مقایسه کنید نشان می دهد.
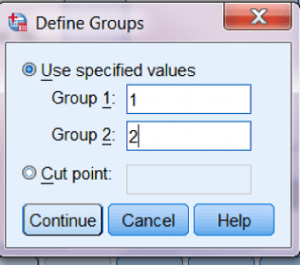
با کلیک روی دکمۀ Define Groups می توانید این کار را انجام دهید.
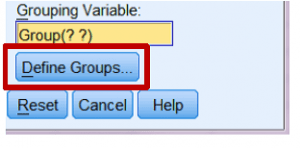
پس از این کادر دیالوگ Define Groups باز می شود و می توانید کدهای عددی را برای هر وضعیت آزمایشی که دارید مقایسه می کنید وارد کنید.
در این مورد، ما از “۱” برای کسانی که زوج را غریبه و از “۲” برای کسانی که زوج را دارای رابطه می دانستند استفاده می کنیم.
بدین ترتیب، باید اعداد ۱ و ۲ را به کادرهای ورودی Group 1 و Group 2 که در اینجا نشان داده می شود اضافه می کنیم.
بعد از آنکه هر دو عدد را وارد کردیم دکمۀ ادامه را باید فعال کنیم. برای ادامه روی continue کلیک کنید.
اکنون باید بهتحلیل آماری SPSS بگویید می خواهید کدام متغیر وابسته را به تحلیل اضافه کنید.
برای این کار، Willingness_Score را انتخاب کنید
و روی دکمۀ پیکان بالایی کلیک کنید تا متغیر به پنجرۀ Test Variable(s) اضافه شود.
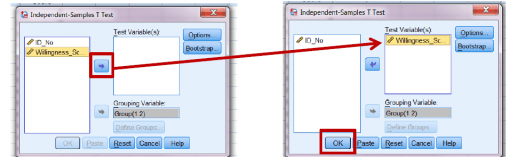
اکنون هر دو متغیر اضافه شده اند. برای اجرای تحلیل، روی OK کلیک کنید.
پنجرۀ خروجی به شما این امکان را می دهد که نتایج آزمون t را بررسی کنید: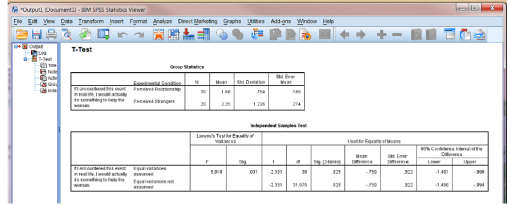
توجه داشته باشید که خروجی دارای دو قسمت است.
این دو قسمت موارد زیر را نشان می دهد:
۱) آمار توصیفی
۲) آمار استنتاجی
بهتر است نگاهی دقیق تر به کادرهای خروجی بیندازیم.
آزمون T مستقل در spss
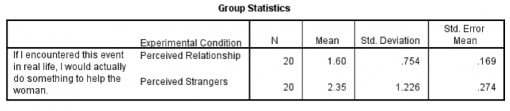
- کادر اول آمار توصیفی گروه ها را نشان می دهد.
- قبل از اینکه هر کار دیگری انجام دهید، بهتر است همیشه اول این کادر را بررسی کنید.
- با این کار می توانید به نگرش اولیه به طرح داده های خود دست یابید.
- در این جدول می توانید مشاهده کنید که میانگین نمره یا اسکور رضایت برای شرکت کنندگان در وضعیت رابطۀ دریافتی ۱٫۶۰ و در وضعیت غریبۀ دریافتی ۲٫۳۵ است.
علاوه بر این، از انحراف معیار مشخصاست که تغییر داده ها (یعنی گسترش نمرات) برای گروه غریبه ها کمی (SD=1.23) بیشتر از گروه رابطه (SD=0.75) است.این شیوه ای استاندارد برای گزارش آمارهای توصیفی در شرایطی که می خواهید نتایج خود را گزارش دهید می باشد.
- در نتیجه، با نکاهی به میانگین های خود مشاهده می کنید که به طور متوسط شرکت کنندگانی که تصور می کردند زوج در حال نزاع با هم رابطه دارند احتمال اینکه تمایل به مداخله داشته باشند از شرکت کنندگان که زوج را با هم غیبه می دانستند کمتر بود.
اما چگونه باید تفاوت بین میانگین ها را تفسیر کرد؟ برای پی بردن به اینکه آیا از لحاظ آماری تفاوتی بین نمرات وجود دارد ، در مرحله بعد باید نگاهی به جدول آمار استنتاجی بیندازید.

آزمون T مستقل در spss
این جدول آمار استنتاجی شما را نشان می دهد: خروجی آزمون t مستقل. نیازی نیست در خصوص تمام ستون های اینجا خود را نگران کنید( بسیاری از قسمت های جدول فقط برای سطح پیشرفته لازم است).
بخش های کلیدی جدول در قسمت بالا مشخص شده است و در قسمت زیر توضیح داده خواهد شد:
– آزمون لون برابری واریانس ها:
یکی از فرضیات آزمون t مستقل این است که دو گروهی که با هم مقایسه می کنید دارای پراکندگی نمرات مشابه هستند.
(در غیراینصورت با عنوان همگنی یا برابری واریانس تلقی می شوند).
این ستون ها به ما می گویند که آیا مورد همین است یا نه.
چنانچه مقدار F معنی دار باشد، این وضعیت نشان می دهد که تفاوت های معنی دار آماری در شیول پراکندگی داده ها وجود دارد و با فرض همگنی مطابقت نداشته است.
توجه داشته باشید که جدول خروجی دارای دو ردیف است:
وقتی واریانس ها با هم برابر باشند از یکی استفاده می کنیم و وقتی برابر نباشند از ردیف دیگر استفاده می کنیم.
در این نمونه، نمی توانیم واریانس ها را با هم برابر فرض کنیم.
زیرا مقدار F معنی دار است (p = .031).
بدین ترتیب، ما فقط باید مقادیر ردیف دوم جدول را بخوانیم.
آزمون t برابری تحلیل آماری میانگین ها:
در این ستون آمار آزمون t وجود دارد. این بخش به هفت بخش فرعی تقسیم می شود. اما فقط سه ستون در این مرحله مهم هستند. این سه ستون عبارتند از labelled t، df و sig (دنباله ای).
در این موقعیت شما تعیین می کنید که آیا فرضیۀ مورد آزمون تأیید شده است یا نه.
– مقدار t بدست آمده از t: این مقدار آمار آزمون t است که SPSS ماسبه کرده است. هر چه مقدار t بیشتر باشد، احتمال اینکه نتایج بصورت تصادفی رخ داده باشد کمتر است.
پیش از اینکه از کامپیوتر برای تحلیل داده ها استفاده شود، مقدار t به صورت دستی با استفاده از فرمول محاسبه می شد.
مقدار به دست آمده سپس با مقدار بحرانی در جدولی به نام توزیع توزیع t مقایسه میشد.
SPSS ما را از انجام همۀ این کارها معاف کرد.
درجۀ ازادی تحلیل آماری df:
در اکثرآزمون های آماری با درجۀ ازادی مواجه خواهید شد.
درجۀ آزادی مقداری است که از آن برای نمایش اندازۀ نمونه یا نمونه های مورد استفاده در یک آزمون آماری استفاده می شود و باید حتما گزارش شود.
شیوۀ گزارش درجۀ آزادی در ازمون های آماری مختلف متفاوت است.
اما باید قبل از اینکه معنی داری نتیجه آزمون بررسی شود به دقت و درستی محاسبه گردد.
زیاد نگران این مسئله نباشید. SPSS خود به بصورت خودکار مقدار آن را برایتان محاسبه می کند.
اما باید توجه کنید که مقدار df با آزمون های مختلف tهمیشه نزدیک به تعداد کل شرکت کنندگان است.
Sig تحلیل آماری (دو دنباله ای):
میزان معنی داری (که به آن احتمال یا مقدار p) نیز می گویند در مورد این احتمال به ما می گوید که آیا نتایج بصورت تصادفی رخ داده است یا نه.
در صورتی که این مقدار کمتر از .۰۵ باشد، فرضیه تأییدد می شود.
در صورتی که بیشتر باشد، فرصیه بخاطر صفر یا خنثی بودن رد می شود که به معنی این است که هیچ تفاوتی بین دو گروه وجود ندارد.
در خصوص آزمون t مستقل،نرمافزار SPSS آزمون را در میزان معنی داری دو دنباله ای به صورت پیش فرض می سنجد.
برای دستیابی به احتمال یک دنباله ای ( در صورتی که فرضیه یک جهتی باشد) مقدار p به نصف تقسیم می شود.
در این موقعیت، می توانیم یک فرضیۀ یک دنباله ای مورد آزمون قرار دهیم مبنی بر اینکه افرادی که فکر می کردند بین زوج در حال نزاع رابطه ای وجود دارد احتمال اینکه در نزاع مداخله کنند از کسانی که خلاف این تصور می کردند کمتر خواهد بوداگر این کار را می کردیم، مقدار p 0.013 می شد (۱ دنباله ای).

برای بررسی خروجی به چه چیزی نیاز داریم؟
هنگامی که نتایج آزمون t را یادداشت می کنید،
باید از طریق فرمول زیر مشخص کنید که آیا آزمون معنی دار بوده یا نه:
t (df) = t value, p = p value
در این فرمول اعداد مربوطه را در قسمت هایی که زیر آن خط کشیده شده وارد کنید.
در مورد این مثال خاص، متوجه شدیم که آزمون t معنی دار است.
ارزش p کمتر ۰٫۰۵ (p< .05) است.
t(31.58) = -2.33, p = 0.026
یافته ها چه چیزی به ما تحلیل آماری می گویند؟
زمانی که میخواهید یافته های خود را تفسیر و یادداشت کنید،
باید از اطلاعات هر دو آمار توصیفی و استنتاجی استفاده کنید.
ترتیب ارائۀ این دو آمار اصلا مهم نیست.
اما همیشه کار خود را با تفسیر واضح نتایج داده ها به پایان برسانید.
- مرحلۀ اول: می توانید طرح داده های خود را با استفاده از میانگین و انحراف معیار اولین جدول خروجی توصیف کنید. در این مورد، می توانید به صورت زیر تفسیر خود را بنویسید:
مرحلۀ دو: از حروف و اعداد برای گزارش رسمی اختلاف معنی دار یا غیرمعنی دار استفاده کنید.
آزمون t مستقل نشان داد که این طرح معنی دار است t(31.58) = -2.33, p < 0.05.
- مرحلۀ سه: در پایان، برای تفسیر و خلاصه سازی آنچه از فرضیه اتان متوجه شده اید باید این اطلاعات را در کنار هم قرار دهید.