
محاسبه آزمون کای دو در spss
این آزمون از نوع ناپارامتری یا ناپارامتریک است و برای ارزیابی همقوارگی متغیرهای اسمی به کار میرود.
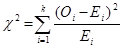
که در آن
O فراوانیهای مشاهده شده
E فراوانیهای مورد انتظار
این آزمون بدون توزیع است. فراوانیهای مورد انتظار نباید در هیچ مقوله ای صفر باشد.
مجموع مقوله هایی که مقدار مشاهدات مربوط به آنها کمتر از ۵ است، نباید بیش از ۲۰ درصد کل مقوله ها باشد.
این آزمون تنها راه حل موجود برای آزمون همقوارگی در مورد متغیرهای مقیاس اسمی با بیش از دو مقوله است.
بنابراین کاربرد خیلی زیادتری نسبت به آزمونهای دیگر دارد. این آزمون نسبت به حجم نمونه حساس است.
تاریخچه محاسبه آزمون کای دو در spss :
این آزمون برای اولین بار در سال ۱۹۹۰ میلادی توسط کارل پیرسُن و برای آزمون «خوبی برازندگی توزیع» (Goodness of fit) به کار برده شد.
برای به دست آوردن آزمون کای دو ابتدا از منوها موارد زیر را انتخاب می کنیم.
Analyze > Descriptive statistics > crosstabs
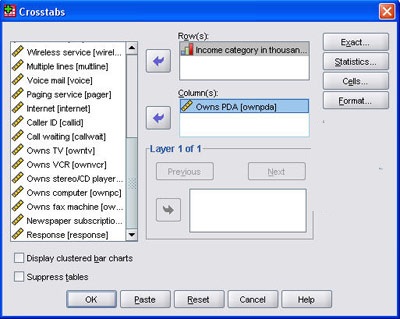
کادر گفتگوی crosstabs باز می شود و مانند شکل زیر در قسمت سطر (Rows) متغیر درآمد inccat و در قسمت ستون (columns) متغیر مالکیت دستگاه دیجیتالی ownpda را وارد کرده و بر روی گزینه statistics کلیک می کنیم.
کادر گفتگوی Crosstabs:statistics شکل زیر باز می شود گزینه chi-Square را فعال و به ترتیب

بر گزینه های Continue و ok کلیک می کنیم.
 فرضیات بدست آمده آزمون به صورت زیر می باشد:
فرضیات بدست آمده آزمون به صورت زیر می باشد:
– فرض صفر: بین متغیر ها رابطه وجود ندارد.
– فرض مقابل: بین متغیر ها رابطه وجود دارد
همان طور که از جدول بالا مشخص است مقدار آماره کای دو برابر ۳۷٫۶۷۷ و احتمال معنی دار بودن برابر صفر است بنابراین فرض صفر که حاکی از عدم رابطه بین متغیر هاست رد می شود و نتیجه می گیریم که بین دو متغیر درآمد و مالکیت PDA رابطه وجود دارد.
نکته:
- همواره باید به پیغام زیر جدول توجه کنیم و اگر مقدار مورد انتظار در سلولی کمتر از ۵ شد با ادغام کردن این مشکل را بر طرف کنیم.
رسم نمودار برای جدول متقاطع در نرم افزار spss
اطلاعات از فایل demo برمیداریم و همانطور که میبینید در این فایل عوامل موثر بر خرید افراد مورد تجزیه و تحلیل آماری قرار گرفته است.
مثال:
متغیرهای مالکیت دستگاه دیجیتالی (ownpda)،
میزان درامد افراد به صورت طبقه بندی شده (inccat)
سطح تحصیلات (ed)
در انتها نتایج یک جدول متقاطع را در نمودار ستونی نشان داده شده است.
برای به دست آوردن نمودار ستونی دسته بندی شده (Clusterd bar charts) ابتدا از منوها موارد زیر را انتخاب می کنیم.
Analyze > Descriptive statistics > crosstabs
کادر گفتگوی crosstabs باز می شود و مانند شکل زیر در قسمت سطر (Rows) متغیر درآمد inccat و در قسمت ستون (columns) متغیر مالکیت دستگاه دیجیتالی ownpda را وارد کرده و گزینه Display clustered bar charts را فعال می کنیم.
شکل زیر به دست می آید.
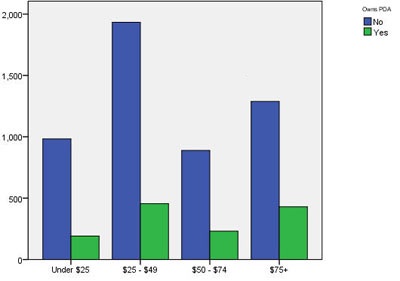
با توجه به اینکه تعداد نمونه ها در گروه های مختلف درآمد برابر نیستند بنابراین مقایسه طول ستون ها در گروه های مختلف درامد امکان پذیر نیست.
هدف اصلی این نمودار:
مقایسه طول ستونها در هر دسته و بررسی وجود الگو در دسته های مختلف است بنابراین نیاز است نموداری به دست اوریم که بر حسب درصد بیان شده باشد.
نمودارهای ستونی پشته شده تحلیل آماری:
در نمودارهای ستونی دسته بندی شده می توان ستون ها را بر روی هم قرار داد که نتیجه آن نمودار ستونی پشته شده (stack) است.
به طور ایده آل می خواهیم تمام ستونها طول برابری داشته باشند تا بتوانیم به سادگی نواحی مختلف ستون ها را با هم مقایسه کنیم. در حقیقت نموداری می خواهیم که محور عمودی بر حسب درصد باشد و تمام ستون ها به صورت ۱۰۰ درصد نشان داده شوند.
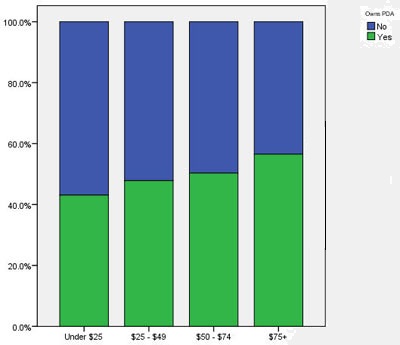
همان طور که از شکل فوق مشخص است با افزایش درآمد مالکیت نیز افزایش یافته است
مراحل برای به دست آوردن نمودار ستونی پشته شده تحلیل آماری
Graphs > legacy Dialogs > Bar
در کادر گفتگوی Bar charts شکل زیر گزینه Bar stackd را انتخاب و بر گزینه Define کلیک می کنیم.

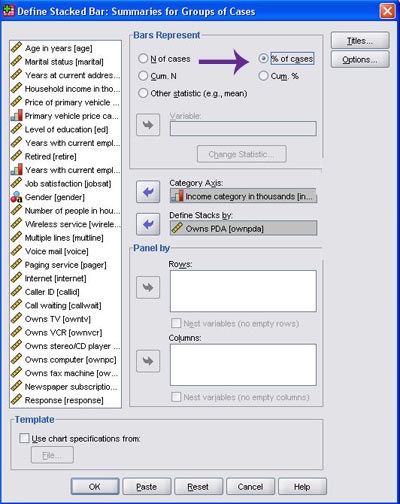
در کادر گفتگوی Define Stacked Bar شکل زیر:
در قسمت Bar represent گزینه % of cases را فعال کرده
و در قسمت Catgory Axis متغیر inccat
و در قسمت Define clusterd by متغیر Ownpda را وارد و بر گزینه ok کلیک می کنیم.
معرفی گروه علمی پژوها
جهت درخواست سفارش تحلیل آماری کلیک نمایید یا با شماره ۰۹۳۵۷۲۵۸۴۲۵ یا info@pajuha.ir ارتباط برقرار نمایید.